1. 문제 정의
저번 게시글을 통해 bulk insert를 하니, 단순 조회 api도 오랜 시간이 걸리는 것을 경험할 수 있었습니다.
서비스가 활성화될 수록 데이터는 쌓일 것이기 때문에, 이를 해결해보도록 하겠습니다.
2. 쿼리 분석
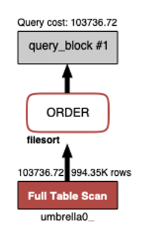
조회 쿼리를 분석해보니, Full Table Scan을 하고 있는 것을 알 수 있습니다.
Full Table Scan이란 -----.
따라서 이러한 쿼리들이 많이 있다면 API 성능은 떨어질 수 밖에 없습니다.
3. 문제 해결
3 - 1. Index 추가
위의 문제를 해결하기 위해 Index를 추가해보도록 하겠습니다.
select
umbrella0_.id as id1_9_,
umbrella0_.created_at as created_2_9_,
umbrella0_.deleted as deleted3_9_,
umbrella0_.etc as etc4_9_,
umbrella0_.missed as missed5_9_,
umbrella0_.rentable as rentable6_9_,
umbrella0_.store_meta_id as store_me8_9_,
umbrella0_.uuid as uuid7_9_
from
umbrella umbrella0_
where
umbrella0_.deleted=0
order by
umbrella0_.id asc limit 5 offset 0;여기서 문제가 되는 부분은 where절로 추정됩니다.
delete에 index가 없기 때문에 full table scan이 일어나는 것을 추정되기에 index를 추가해보도록 하겠습니다.
ALTER TABLE umbrella ADD INDEX idx_deleted (deleted);3 - 2. 성능 비교
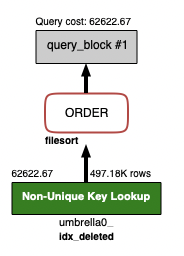
Index를 추가하니, index를 타고 데이터가 조회된 것을 볼 수 있습니다.
Query Cost도 103736에서 62622로 40% cost가 감소된 것을 볼 수 있습니다.
이처럼 index를 활용한다면 쿼리의 성능을 개선할 수 있을 것입니다.
4. 마무리
이번 게시글을 통해 간단한 쿼리의 성능을 개선하는 방법을 알아보았습니다.
다음 게시글에서는 JPA에서 생성해주는 쿼리는 어떻게 성능을 개선할 수 있을지 제가 고민한 점과 해결한 방법을 공유하겠습니다.